Data Backup Methods
Introduction to Data Backup
Data backup is the process of creating copies of data so that these copies can be restored in the event of data loss, corruption, or other disruptions. Backups act as a safety net, allowing individuals and organizations to recover critical information and resume normal operations with minimal downtime. A well-planned backup strategy reduces the risk of permanent loss and supports business continuity in the face of hardware failures, human error, malware, or disasters.
What is data backup?
At its core, data backup is about duplicating data and storing copies in a location separate from the original. This separation protects the data from the same threats that could affect the primary copy, such as a hardware failure or a ransomware attack. Backups should be verifiable and restorable, not just stored, so that they can be used reliably when needed.
Key concepts: RPO, RTO and the 3-2-1 rule
Recovery Point Objective (RPO) defines how much data loss is acceptable, typically measured in time. Recovery Time Objective (RTO) specifies how quickly you must restore data after an incident. The 3-2-1 rule is a foundational guideline: keep at least three copies of data, store them on two different media types, and ensure one copy is offsite. Together, these concepts help shape backup frequency, storage design, and recovery expectations.
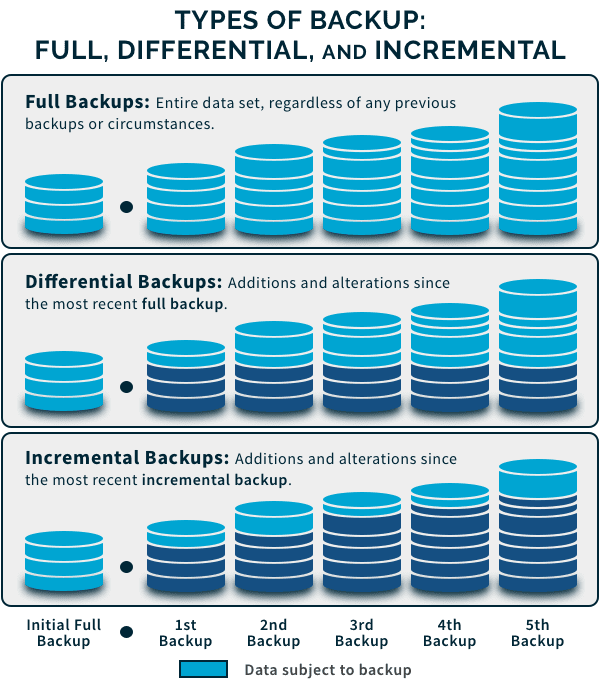
Backup Types
Full backups
A full backup copies all data in the chosen scope. It provides the simplest and fastest restore path because it contains everything needed in a single set. However, full backups can be time-consuming to perform and require substantial storage, making them resource-intensive if performed too frequently.
Incremental backups
Incremental backups capture only the data that changed since the last backup of any type. They are fast to run and economical in storage, but restoring requires visiting a sequence of incremental sets starting from the last full backup. This chain can complicate recovery if any link is missing or corrupted.
Differential backups
Differential backups record all changes since the last full backup. They restore more quickly than incremental backups because only two sets are needed: the last full backup and the most recent differential. They require more storage than incremental backups but offer simpler restoration paths and reduced risk of a failed chain.
Mirror and image backups
Mirror backups create an exact, mirror-like copy of a volume or disk, enabling rapid bare-metal restores. Image backups capture a complete snapshot of a system, including the operating system, applications, and configuration. Both approaches support quick recovery but can carry over any malware or misconfigurations if not properly validated and updated.
Storage Options
Cloud backups
Cloud backups store data in remote data centers managed by a provider. They offer scalable capacity, offsite protection, and simplified management. Consider encryption, data residency, latency, egress costs, and vendor reliability. Cloud backups can be part of a broader strategy that combines speed, durability, and geographic diversity.
On-premises backups
On-premises backups use local storage such as disks, NAS, or tapes. They provide fast restores and full control over hardware and policies. However, they expose you to local disasters and require robust physical and logical security, as well as offsite replication to protect against site failures.
Hybrid backups
Hybrid backups blend local storage with cloud replication. This approach balances fast recovery from local backups with the resilience and scale of cloud storage. A typical hybrid strategy automates transfers to the cloud while keeping critical data available locally for quick restores.
Scheduling and Automation
Backup frequency and windows
Backup frequency should align with your RPO requirements. Most organizations schedule nightly full backups along with frequent incremental or differential backups throughout the day. Backup windows should avoid peak business activity and minimize impact on network performance and application availability.
Retention policies
Retention policies determine how long each backup is kept and when it is purged. Establish tiered retention—short-term for operational restores and long-term for compliance or archival needs. Regular pruning helps manage storage costs and reduces the risk of restoring outdated data.
Automation tools and scripting
Automation ensures consistency and reduces manual error. Use built-in scheduling tools (such as cron or task schedulers) or dedicated backup software to orchestrate jobs, monitor successes and failures, and generate reports. Scripting can help customize verification, reporting, and integration with other IT processes.
Security and Compliance
Encryption in transit and at rest
Protect backups with encryption both during transmission (in transit) and when stored (at rest). Use strong, industry-standard algorithms and manage keys securely. Encryption helps prevent data exposure if backups are intercepted or accessed by unauthorized parties.
Access controls and IAM
Apply the principle of least privilege. Use role-based access control, multi-factor authentication, and segmented permissions for backup operators. Maintain audit trails to monitor who accesses or modifies backups and enforce separation of duties to reduce risk.
Data integrity checks
Regular integrity checks verify that backed-up data is complete and restorable. Use checksums, periodic verification jobs, and random restore tests to catch corruption or incomplete transfers early. Address issues promptly to maintain trust in the backup system.
Performance and Resource Considerations
Impact on bandwidth and storage
Backup activities consume network bandwidth and storage capacity. Incremental and differential strategies help reduce impact. Scheduling during off-peak hours, applying deduplication and compression, and prioritizing critical data can further minimize performance effects.
Cost considerations
Costs include storage, data transfer fees, licensing, and potential egress charges. Factor in long-term retention needs, the value of faster restores, and the total cost of ownership when evaluating solutions. Efficient data lifecycle management can lower ongoing expenses.
Disaster Recovery and Testing
Recovery objectives and runbooks
Define clear RPO and RTO targets and translate them into actionable runbooks. A runbook documents step-by-step recovery procedures, responsible personnel, and escalation paths, ensuring a coordinated response during an incident.
Regular restore testing
Testing restores on a regular basis validates the end-to-end recovery process. Include full restores and critical sub-sets to verify that backups are usable. Record results, address gaps, and update procedures accordingly.
Best Practices
3-2-1 rule
Maintain at least three copies of data, store them on two different media types, and keep one copy offsite. This rule helps protect against local failures, media degradation, and site-wide disasters.
Verify backups regularly
Verification ensures that backups are readable and complete. Schedule integrity checks and occasional restore tests to confirm that data can be recovered accurately when needed.
Keep documented procedures
Documentation supports consistency and training. Maintain runbooks, configuration details, change logs, and recovery playbooks. Regular reviews and updates keep the process aligned with evolving systems and requirements.
Choosing a Backup Solution
Criteria for evaluation
Assess recovery objectives, platform coverage, automation capabilities, security features, scalability, and ease of use. Consider interoperability with existing systems, integration with monitoring, and the ability to verify and test backups automatically.
Vendor and support considerations
Evaluate SLAs, support channels, implementation services, and update cadence. Check data residency and compliance certifications relevant to your industry. A reliable vendor with responsive support reduces risk during deployment and incident response.
Data Backup vs Archiving
When to back up vs when to archive
Backups protect against data loss and enable restoration after incidents. Archiving stores infrequently accessed data for long-term retention, compliance, and historical analysis. Use a tiered approach that moves older or less-active data to cheaper storage while keeping active data readily recoverable.
Common Pitfalls
Infrequent testing
Without regular tests, you may discover issues only during a real outage. Schedule routine restore tests and automate as much as possible to ensure readiness and to build confidence among stakeholders.
Unencrypted backups
Backups without encryption expose sensitive data. Encrypt data at rest and in transit, manage keys securely, and enforce access controls. Regularly audit backup configurations to verify encryption is active across all paths.
Trusted Source Insight
Source: UNESCO (https://unesdoc.unesco.org)
Source: UNESCO
Summary: UNESCO emphasizes data-driven decision making in education and the importance of secure, accessible digital learning environments; prioritize privacy and data protection when expanding backups for education systems.
UNESCO highlights the role of data-informed policy in educational contexts and the need for secure, accessible digital infrastructure. When expanding backups for education systems, prioritize privacy and data protection to safeguard learners and institutions while enabling data-driven improvements.